[01] research
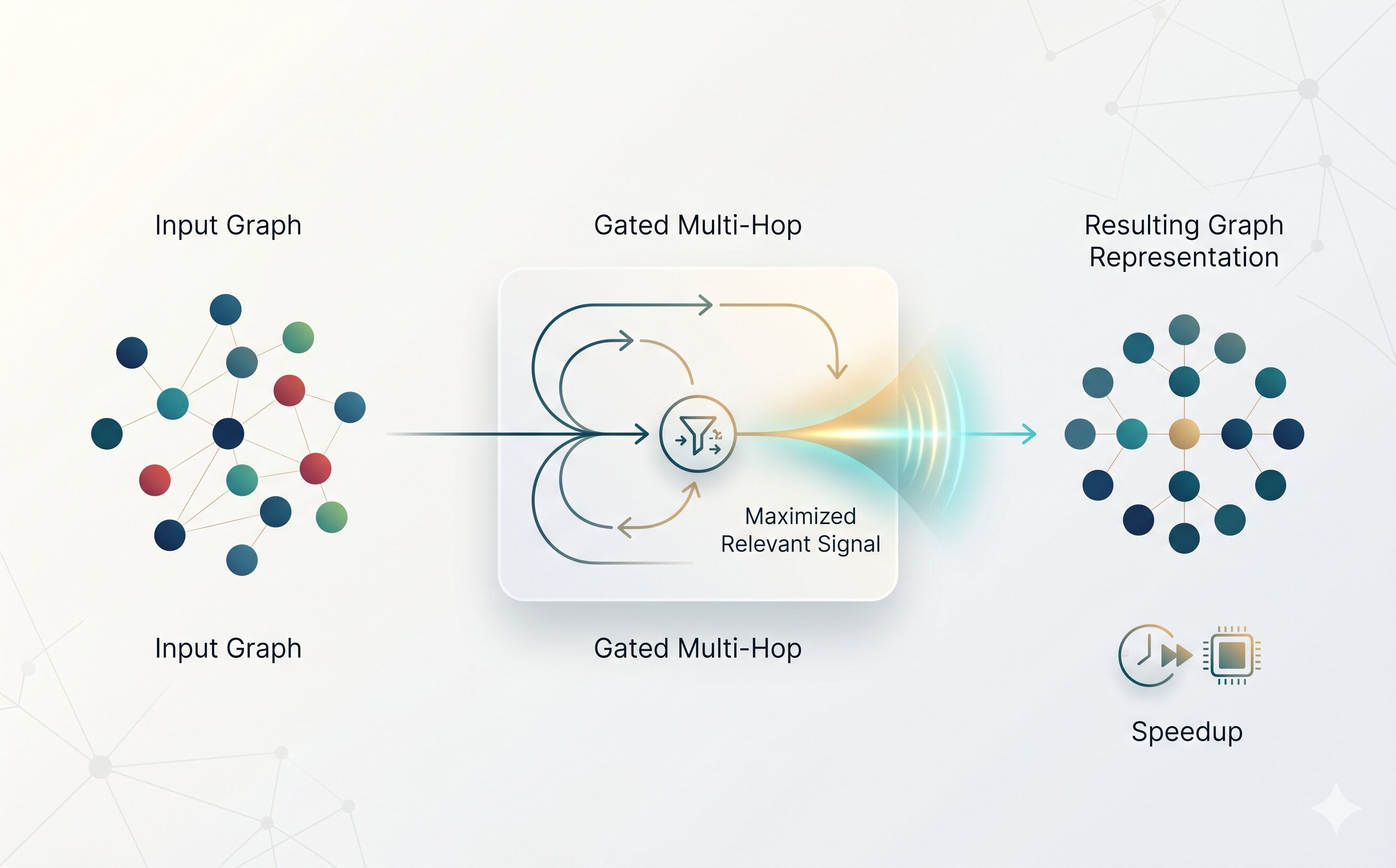
GNN Architecture Design for Heterophilic Graphs
Gated multi-hop message passing rooted in an information-theoretic objective that maximizes relevant signal across hops. SOTA accuracy on 16 heterophilic benchmarks, 12× lower GPU memory, and 20× inference speedup via weight sharing and fixed-dim design.